Reshmi Ghosh

Senior Applied Scientist, Microsoft (MSAI)
Reading the residual stream: a mechanistic study of misgendering in Gemma and Aya
Posted June 06, 2026
In 2023, I made a deliberate bet on where to spend my side-quest research time: mechanistic interpretability of large language models. The thesis was simple, even if it doesn’t sound like a hot take: the shortest path to a better product is understanding why the model behaves the way it does – not making it bigger, not adding another loss term, not chasing another evaluation suite. I have been an advocate of interpretability even before November 2022. Explaining (using tools like LIME, SHAP, etc.) why machine learning models were predicting a specific outcome helped me in:
- deciphering reconstructed electricity demand patterns (synthetic generated data) for 40 years in the past, for my PhD thesis,
- optimizing small language models/machine learning models tuned for M365 suite, deployed in edge devices, under high-stake constraints (device memory, latency, and accuracy),
- determining root causes for failures (preemptively) in cloud service (Azure VMs) and extrapolating those patterns to associated micro-services.
When you genuinely understand what’s happening inside the model, you stop being surprised by it, you spot the gaps that benchmarks hide, and you ship features that hold up in production rather than fall apart at the user-experience layer.
This post is a stake in the ground on what that bet looked like in practice – what I worked on, what surprised me, and where I think the field needs to go next, especially as I gear up to welcome a new Intern this year to uncover some production model behaviors.
What is mechanistic interpretability?
“Mechanistic interpretability” is a broadening label, that enables deciphering model “circuits” using small toy transformers. What I am/was particularly fasinated with, is the tooling probing real production-scale language models to understand which internal representations get used when, especially when the model has both parametric memory and retrieved context to draw from.
This is also where it parts ways with the older, model-agnostic interpretability stack — methods like LIME and SHAP that estimate which inputs mattered for a single prediction by perturbing a black-box model from the outside. Those methods are useful as a sanity check, but they are post-hoc, correlational, and silent on how the model actually arrived at the output; they tell you a story about the prediction without giving you a handle on the computation behind it. For an LLM-plus-retriever system where the failure mode is “the model deferred to context it shouldn’t have,” LIME-style importance scores describe the symptom but don’t tell you which sub-network to instrument or steer. Mechanistic interpretability opens the model, identifies the specific representations and circuits responsible, and — crucially — gives you a causal lever you can pull at inference time. That shift from explanation-as-description to explanation-as-intervention is what makes it product-shaping rather than just diagnostic.
Experiments with Mech Interpretability and understanding model behavior
From RAGs to Rich Parameters — arXiv 2406.12824
The question this paper asks is direct: when a language model is given retrieved context plus a query, does it actually use the retrieved context, or does it fall back on what it learned during pre-training? People had hand-waved about this for years, usually arguing one side or the other based on prompt-level tricks. We wanted a mechanistic answer.
We probed activations layer-by-layer and found that production-class LLMs lean heavily on retrieved context, they actively minimize their use of parametric memory when context is available. That sounds like unambiguous good news for RAG. It isn’t. The same property that makes RAG work is the property that makes prompt injection work. The model is wired to defer to whatever you put in its context window; that’s a feature for retrieval and a vulnerability for adversarial inputs. Once we understood the mechanism, it stopped being a surprise that prompt-injection defenses are so hard to get right by patching at the API layer alone.
On Surgical Fine-Tuning for Language Encoders — EMNLP 2023 Findings, arXiv 2310.17041
The precursor to the RAG line. Before I was probing models to understand RAG behavior, I was probing them to understand which layers actually need to move during task adaptation. The finding, that you can get most of the benefit of full fine-tuning by touching a small, principled subset of layers, was itself a small piece of interpretability. It told us layer-level locality matters, and that prepared the ground for the activation-patching work that came later.
What the bet has actually paid back
The learnings from the research are broadly applicable:
- Factual drift in RAG systems. When retrieved context is stale or wrong, models parrot it. We now know mechanistically why: they’re wired to. That changes how you build the retrieval layer, the monitoring layer, and the user-facing fallback behavior.
- Prompt injection hidden in documents and images. The same context-deference that makes RAG good makes it manipulable. Interpretability findings fed directly into how I about prompt injections and adversarial detection now.
- Hallucination patterns. Knowing which layers re-engage parametric memory tells you which interventions actually move the needle versus which are theater. Saves enormous amounts of dev cycles spent on things that won’t generalize.
- Knowing when to not ship a post-trained model. This one is the underrated dividend. Interpretability evidence has, on multiple occasions, been the deciding factor for whether a model variant goes into production. Benchmarks tell you the average; mechanistic analysis tells you the tail.
Following my curiosity about languages and misgendering in language models — cross-lingual gender circuits in Gemma and Aya
Context: I was born into a Bengali family that lived in several states across western and southern India. Bengali for those who don’t know, is a gender-neutral language and doesn’t assign pronouns with objects and verbs. This is in sharp-constrast with Konkani and Hindi (which I had to take up in school as second and third language) and Marathi, which do have genders assigned to verbs and pronouns influence sentence formation to a very large degree. My Bengali knowledge often would overfit my “actual” intelligence to learn gender-dependent languages like Konkani, Hindi, and Marathi, and till date I do not know the protocol on how these languages assign genders to non-living objects, like chair, tables, cars, etc. My abysmally bad non-English scores in exams are a testament to my struggles. Today, if I have to code-switch and speak a non-English language, I generally wing the genders for inanimate objects.
I have observed the best language models today misgender (maybe not as frequently as I do :P), and this behavior is visible even with grounding context. This got me thinking and I wanted to probe whether multilingual LLMs have a cross-lingual gender-resolution circuit: when a model is given a source-language passage and asked to translate it into German (which forces a pronoun choice between Er and Sie), does it actually extract gender from the source-language grammar, or does it default to something else? Four source languages give a clean ladder of how much gender information the source provides:
- English — explicit pronoun gender. Control / upper bound.
- Marathi — both pronoun (तो/ती) and verb (होता/होती) inflect for gender. Strongest grammatical signal of the three Indic options.
- Hindi — gender-neutral pronouns, but verbs inflect for subject gender. Signal sits on the verb form.
- Bengali — no grammatical gender at all. The only cue is the subject’s name.
The dataset is small but deliberate: five female + five male names per language, written in source-language script. The choice to use native names instead of a single shared roster was a direct response to v1 (see appendix below) — v1 embedded European first names (Maria, Carlos, Lisa, …) inside Bengali/Hindi/Marathi sentences, and the script-mixing itself leaked gender signal in a way we couldn’t separate from the source-language grammar. Native names in native script force the model to engage the actual Bengali/Hindi/Marathi name distribution it would see in a real product setting.
| Language | Female names (with romanisation) | Male names (with romanisation) |
|---|---|---|
| Bengali | বদিশা (Bidisha), রাজশ্রী (Rajashree), দেবলিনা (Deboleena), নীলাঞ্জনা (Nilanjana), ঐন্দ্রিলা (Oindrilla) | উৎপল (Utpal), বিমল (Bimal), দেবদিত্য (Debaditya), শায়ন (Shayan), অরবিন্দ (Aurobindo) |
| Hindi | रेशमी (Reshmi), प्रिया (Priya), आरती (Aarti), अंजली (Anjali), काजल (Kajal) | अर्जुन (Arjun), विक्रम (Vikram), राहुल (Rahul), अभिषेक (Abhishek), अमित (Amit) |
| Marathi | साई (Sai), मधुरा (Madhura), अश्विनी (Ashwini), वैष्णवी (Vaishnavi), ओजस्वी (Ojasvi) | साकेत (Saket), अजिंक्य (Ajinkya), चैतन्य (Chaitanya), अमोल (Amol), अनिकेत (Aniket) |
| English | Emily, Sarah, Anna, Lisa, Maria | Alex, Michael, Carlos, Felix, Pedro |
All four name lists were cross-checked with a native or near-native reader of each script, one early Bengali name (ইমন / Iman) was a homograph for an unrelated Bengali word and had to be replaced. (Most Bengali names are of my family members. Also fun-fact if not Reshmi (Hindi language centered), I was to be named Nilanjana, which is deeply rooted in Bengali cultural context -so this was a fun experiment also calibrating how LLMs using my first name and potential first name could misgender me.) That kind of cultural validation is invisible labor that’s easy to skip; in this experiment, skipping it was the difference between a sub-chance probe accuracy and a clean signal.
I ran two models on this: Gemma-2-2B-it and Aya-23-8B (Cohere’s purpose-built multilingual model). For each, I measured two separate things:
- Encoding — a linear probe trained on the mean-pooled residual stream after the model has read the source sentence. Does the model represent the subject’s gender internally?
- Routing — forced-choice scoring across three German continuations with mid-sentence “sie” / “er” pronouns, averaged. Does the model use that internal representation when it generates German?
The separation between encoding and routing is the whole point. A model can encode gender perfectly and still refuse to use it at generation time — and that gap is invisible to standard translation benchmarks but recoverable by mechanistic analysis.
Encoding looks healthy for both models
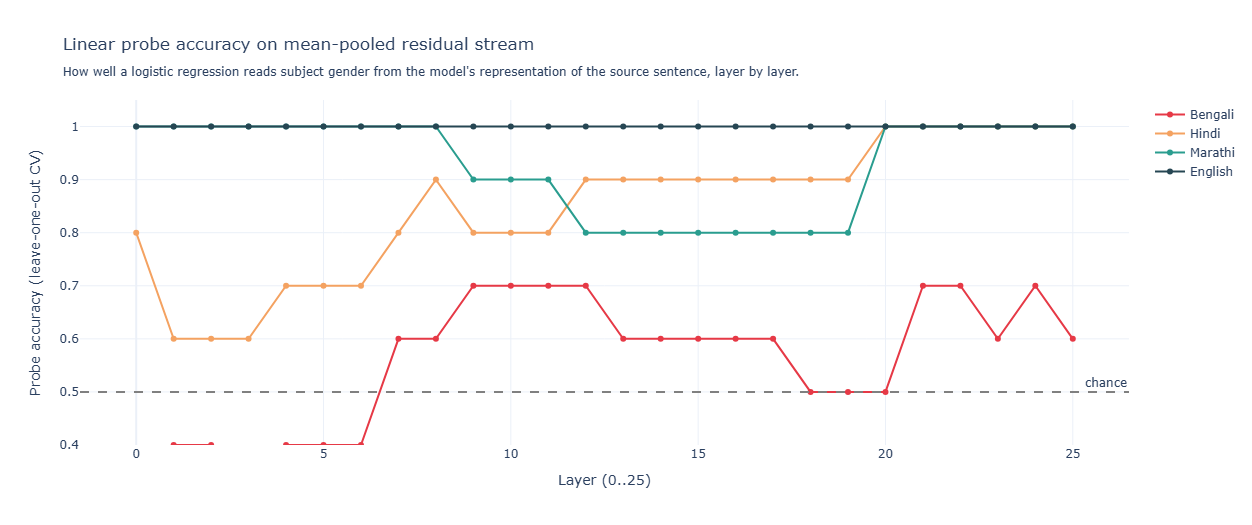
Gemma encodes gender exactly along the predicted ladder: English saturates at layer 0 (explicit pronoun cue), Marathi rises sharply around layer 8 to near-perfect by layer 12, Hindi follows a similar arc, and Bengali sits stable at 0.6–0.7 across most of the network — above chance but not perfect, exactly as you’d expect from a name-only signal.
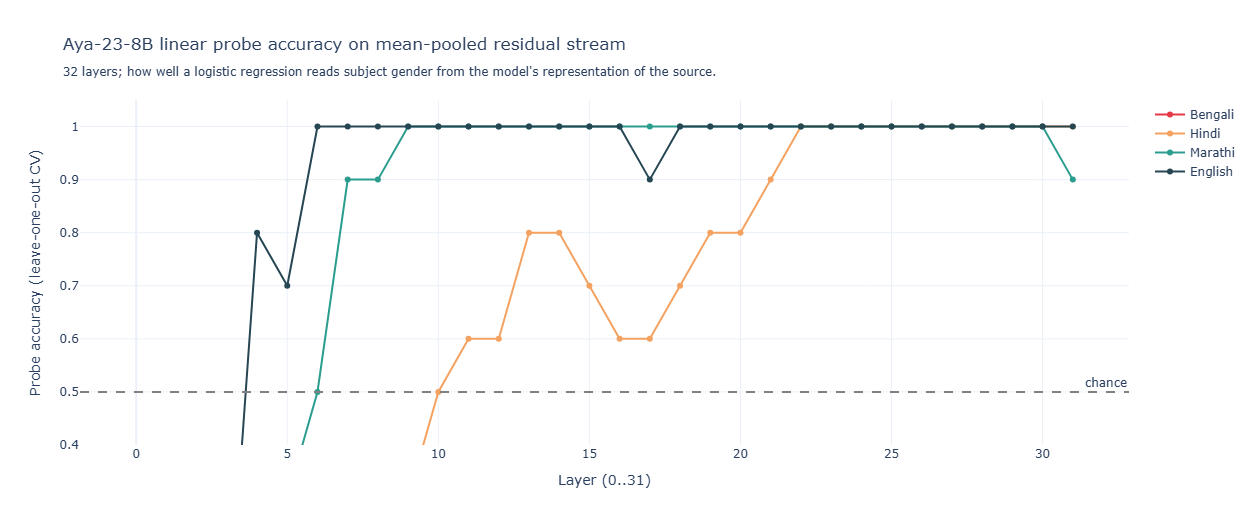
Aya encodes faster: English saturates by layer 6, Marathi by layer 9, Hindi (noisily) by layer 22. This is the multilingual-training dividend showing up mechanistically — Aya has dedicated grammar-extraction circuits that fire earlier in the forward pass than Gemma’s. Bengali is the outlier; I’ll come back to it.
Routing diverges sharply between the two models
This is where the story gets interesting. Here’s the side-by-side comparison of probe peak (encoding) vs. translation accuracy (routing):
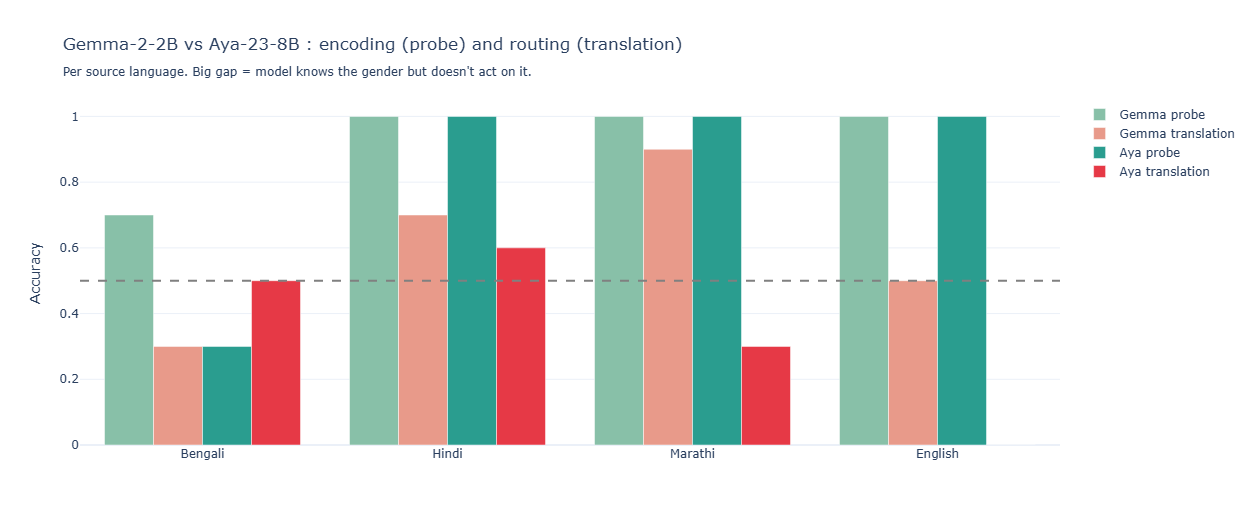
| Language | Gemma probe | Gemma routing | Aya probe | Aya routing |
|---|---|---|---|---|
| English | 1.00 | 1.00 | 1.00 | 1.00 |
| Marathi | 1.00 | 1.00 | 1.00 | 0.50 |
| Hindi | 1.00 | 1.00 | 1.00 | 0.80 |
| Bengali | 0.70 | 0.70 | 0.30 | 0.60 |
Gemma’s encoding and routing are matched everywhere. What the model knows, it uses. The Bengali ceiling at 0.70 is real but explainable — only the name token carries gender information, and Gemma’s grasp of distinctively-Bengali names is partial.
Aya has a large, language-dependent encoding-to-routing gap. Most strikingly: Aya’s Marathi probe accuracy is 1.00 — the model has perfectly encoded the subject’s gender from the Marathi grammatical cues, but Aya’s Marathi translation accuracy is 0.50, chance. The model knows the gender and doesn’t use it. Hindi shows the same pattern at lower magnitude (gap 0.2). English shows no gap. The clearer the grammatical signal, the worse Aya’s routing relative to its encoding.
The translation box plots make the failure mode visible:
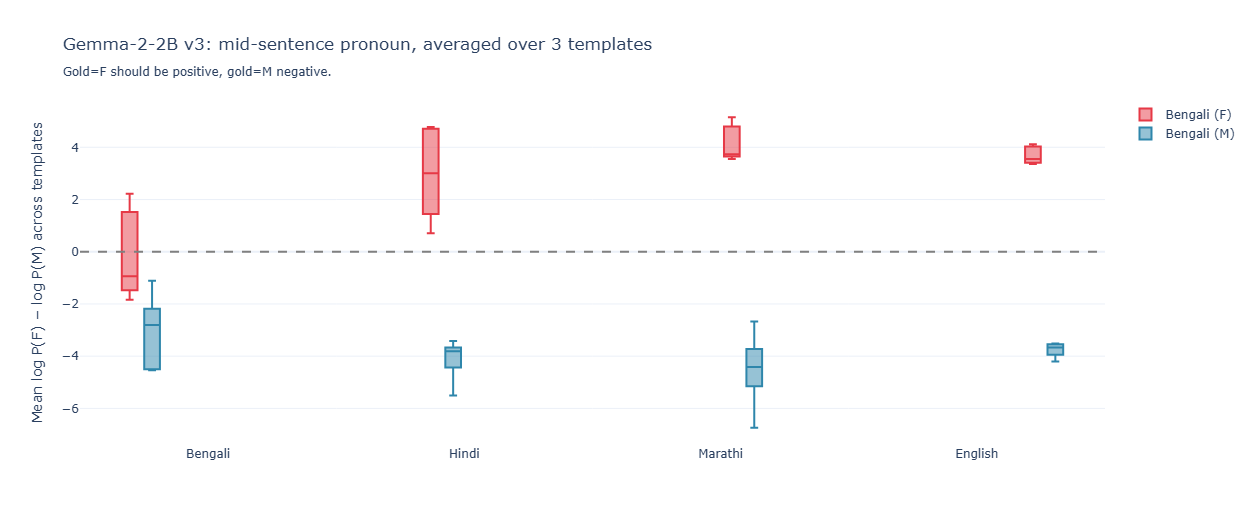
For Gemma every (language × gender) pair separates cleanly: F-boxes positive, M-boxes negative, modest magnitudes.
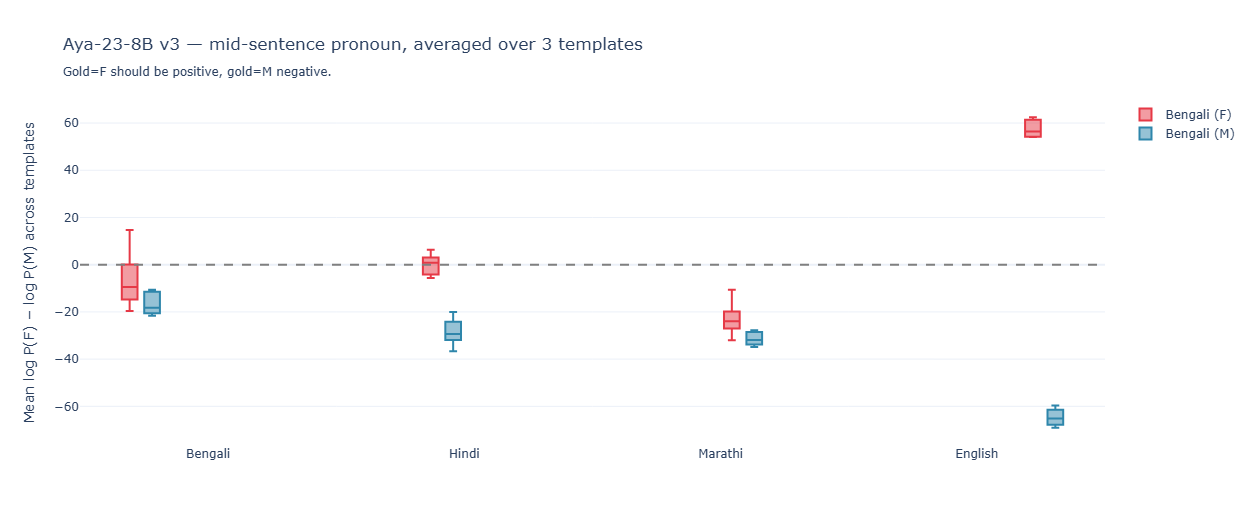
For Aya the F-boxes for Marathi and Bengali sit in negative territory — the model is predicting Er (masculine) for female-subject Marathi and Bengali sentences despite the probe saying it has the right gender information internally. English is clean, with massive magnitudes; the rest of the languages have a quiet masculine default.
What this most likely is
Aya’s behavior reads as a masculine default for non-English source contexts. The model’s German generation distribution is anchored to a strong masculine prior — Er as the unmarked third-person — and only English source context produces a signal strong enough to override it. Indic-language sources, however grammatically rich, get partially or wholly overridden.
This is exactly the kind of bias mechanistic analysis is the right tool for. It doesn’t show up cleanly on translation benchmarks (BLEU-style metrics tolerate pronoun substitutions, especially when the surrounding sentence is otherwise correct). It doesn’t show up on safety evals (it’s not a refusal, not a toxic output). What it is: a language-dependent generation bias that is invisible to standard metrics but recoverable by reading the residual stream. If a downstream product summarizes Marathi or Bengali source documents in German, it will systematically default to masculine pronouns, and no aggregate benchmark will catch it.
The mechanistic finding tells you exactly where to intervene: not in the encoding (it’s fine), not in the source-language data mixture (the model evidently learned the grammar), but in the late-stage generation circuit that decides which pronoun to commit to. That’s a much sharper diagnosis than “Aya has a translation bias” — it tells you which subsystem to audit and which not to bother with.
Caveats I want to be honest about
- Aya Bengali probe at 0.30 is below chance, not at chance. With n=10 and leave-one-out CV, that suggests Aya’s representations of distinctively-Bengali names cluster opposite to their actual gender labels. Most likely cause: Aya’s Bengali training data is thinner than its training data for other Indic languages, so its name-gender associations are weak or idiosyncratic for names like অরবিন্দ (Aurobindo), নীলাঞ্জনা (Nilanjana), etc. The downstream translation accuracy (0.60) is closer to what we’d expect from a model relying on contextual cues rather than name embeddings.
- n=5 per gender per language is small. The direction of every claim is robust to leave-one-out, but the absolute accuracies have ~10% noise. Scaling to ~30 per gender per language is the obvious next step for a paper.
- Native-speaker validation of the dataset was indispensable. v2 with naive-Latin-script names embedded in Indic sentences produced badly confounded results; the cleaned v2.1 dataset (with names natively rendered in source-language script and one homograph removed) gave us the clean signal above. Same lesson applies to anyone running cross-lingual mechanistic experiments.
- Forced-choice scoring needs care. v2 used sentence-start pronouns (“Sie war…” / “Er war…”) and produced uninterpretable numbers because both models have strong sentence-starter priors that swamped the gender signal. v3 uses mid-sentence pronouns averaged across three templates. The artifact disappeared, English routing went from 0.0 to 1.0 for Aya. If you run a forced-choice probe and the numbers are noisy, suspect the prior before suspecting the model.
Where I think this goes next
Three directions I expect to spend time on:
- From probing to intervention. Probing is descriptive. The next bar is causal — can we steer the parametric-vs-context tradeoff at inference time, per query, conditioned on context confidence? That’s where this becomes a directly product-shaping tool rather than a postmortem one.
- Agentic and multi-step reasoning. Single-turn RAG is a relatively clean mechanistic surface. Multi-step agents that loop tool calls, accumulate working memory, and replan over partial successes are where current interpretability methods break down — and where the most valuable next round of research sits.
- Interpretability that survives preference tuning. Many of the cleanest probing results are on base models or supervised-fine-tuned models. The story gets messier after RLHF/DPO. Methodology that holds up post preference tuning is, in my opinion, the highest-leverage open problem in the area.
Appendix — what went wrong before these experiments, and what it taught me
The cross-lingual probing experiment above is v2. The first pass (v1) used a different framing and produced almost no signal, but the way it failed turned out to be the most useful part of the project — it told us what kind of measurement actually works for this question. Worth including here because the negative results are themselves a finding.
v1 setup, briefly
V1 used continuation framing: present a source-language passage followed by a German question — “Was hat diese Person gestern gemacht?” and measure the model’s next-token logit difference for Er vs. Sie. The dataset used European first names (Maria, Carlos, Lisa, Pedro, …) embedded inside Indic-language sentences, on the theory that name-controlled minimal pairs would let us isolate the source-language grammatical signal.
Two things went wrong simultaneously: the prompt contained a feminine grammatical anchor, and the dataset contained a script-mixing confound. The result was that neither model showed a clean cross-lingual signal under v1’s measurement, and we couldn’t tell which part of the setup was responsible.
What the logit-lens looked like in v1
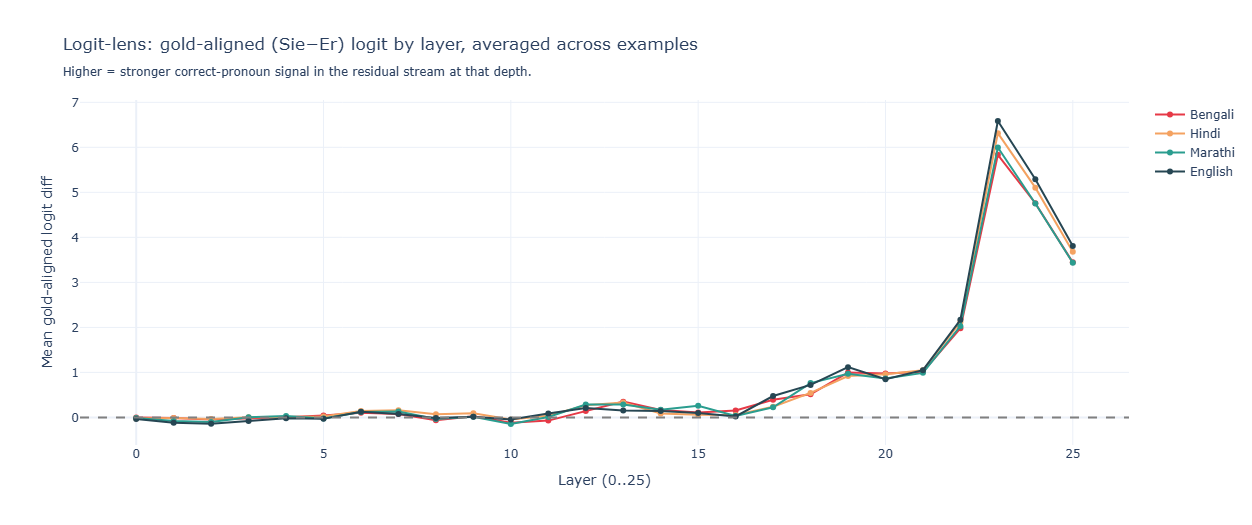
Gemma v1 logit lens. All four source-language curves lie on top of each other across all 26 layers. The pronoun decision crystallizes only at layers 22–23 of 26, and the curves for Bengali (no grammatical signal), Hindi (verb-gender), Marathi (both pronoun and verb gender), and English (explicit pronoun) are within noise of each other. Read literally, this says Gemma has no cross-lingual gender-resolution circuit. The v2 probe later showed this was wrong — Gemma encodes gender from grammar quite cleanly — so what v1 was actually measuring was something narrower. The narrowest interpretation: Gemma was reading the name token, ignoring the surrounding Indic context, and the European names dominated whatever signal there was.
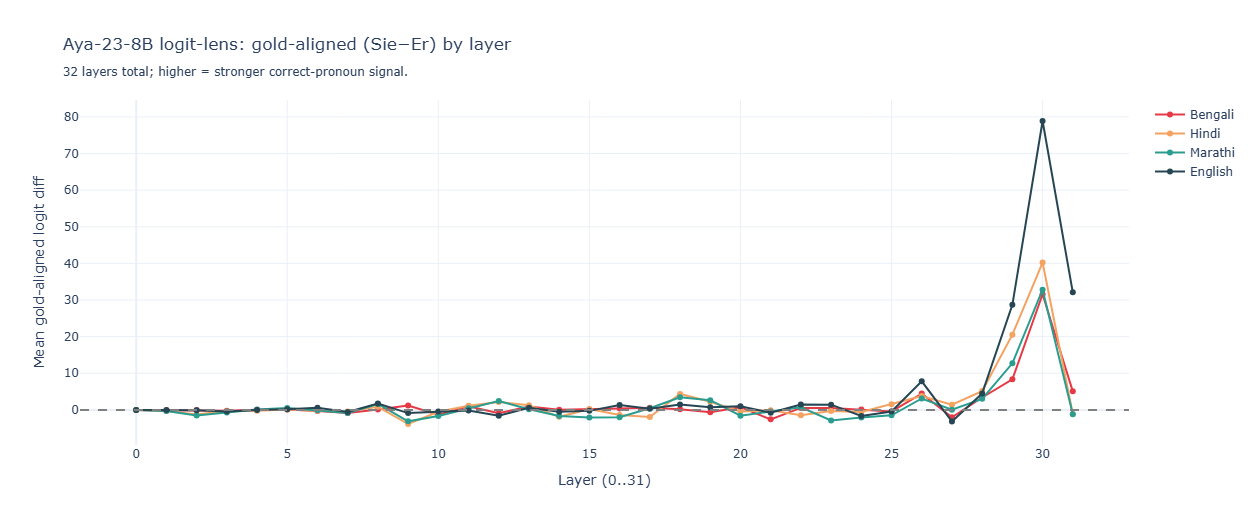
Aya v1 logit lens. Here we do get differentiation — English peaks at ~78, Hindi at ~40, Bengali and Marathi at ~33 — but the absolute magnitudes are tangled up with Aya’s preference for Sie driven by the German prompt’s “diese Person” (grammatically feminine). The relative ordering is suggestive, but you can’t tell from this alone whether Aya was extracting gender from the source or was being pushed by an anaphor in the prompt that we put there ourselves.
Why v2 looks completely different
The probe figures in the main section don’t have the “diese Person” anchor (the model is run on just the source sentence, with no German prompt at all), and they use a forced-choice scoring template that avoids sentence-starter priors. With those two fixes the language ladder that v1 said wasn’t there became immediately visible. The lesson: measurement choice can hide a clean circuit just as effectively as the absence of one. If you have a prior on what the model should be doing and the measurement says it isn’t, doubt the measurement first.
And the activation patching — why this approach doesn’t carry the story
V1 also included cross-lingual activation patching: take the residual stream from a clean English example, splice it into the corresponding (layer, position) of a corrupt Bengali example, and see whether the German pronoun choice gets restored. The hope was to identify a localized circuit responsible for gender attribution.
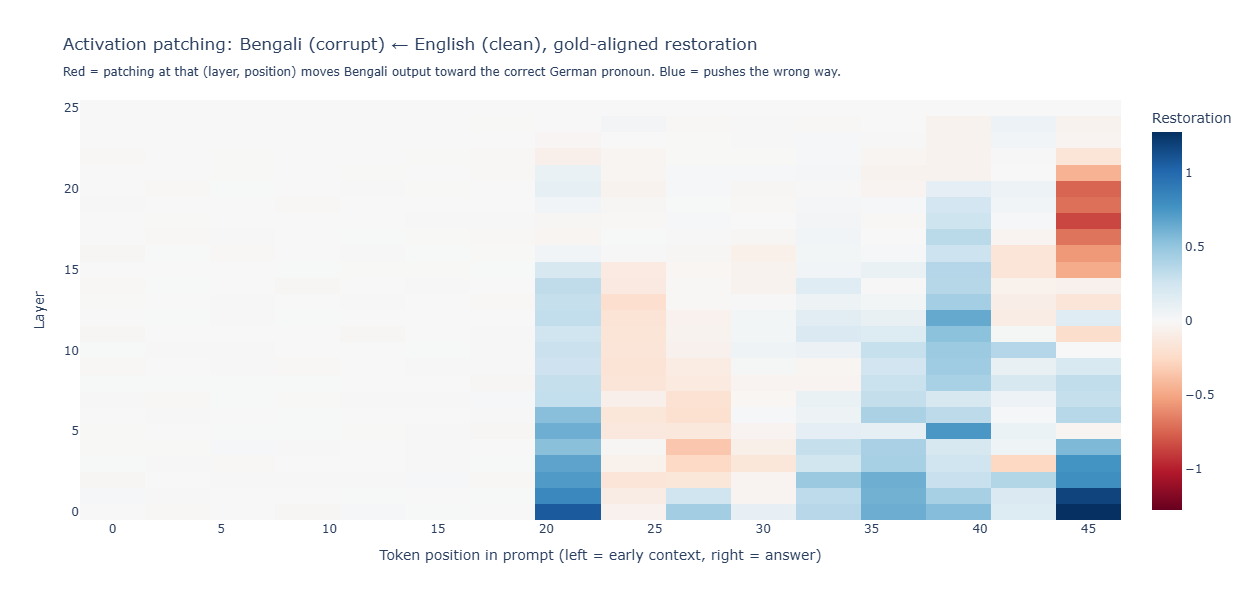
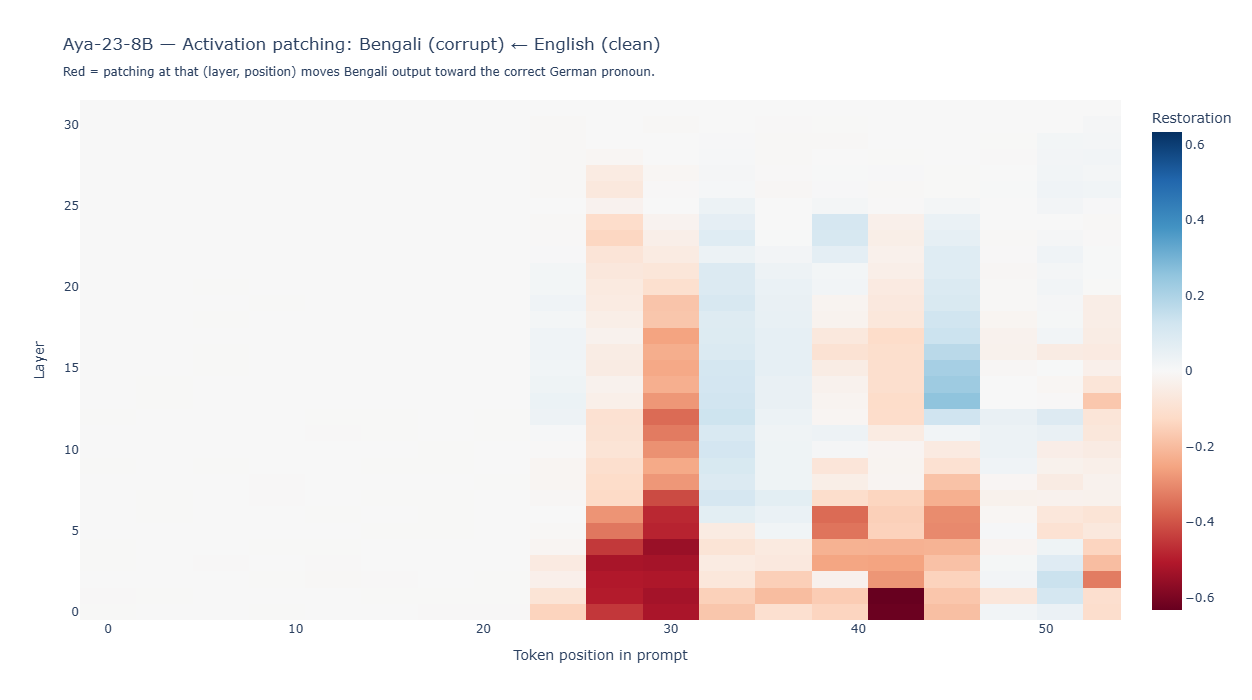
Neither heatmap shows a clean restoration hotspot. Gemma has scattered blue (mild restoration) concentrated in early layers at late prompt positions, and Aya is mostly red (patching makes things worse). I include them here as a methodological warning rather than a finding: cross-prompt activation patching across different scripts and different prompt lengths is fundamentally noisy, and the noise can easily masquerade as either evidence-for or evidence-against a circuit. The Bengali prompt and the English prompt have different token counts (Devanagari and Bengali script tokenize longer than Latin for similar content), and position p=25 in one prompt is not the semantic equivalent of p=25 in the other. Patching there isn’t a controlled intervention — it’s a perturbation whose semantics depend on which arbitrary tokens happened to align by index.
The right way to use activation patching for a question like this is minimal pairs within a single language: e.g., for Hindi, patch between a sentence with masculine verb-form था and one with feminine थी, holding every other token (including the name and the position of the verb) fixed. That gives you a controlled causal intervention. v1’s cross-script patching didn’t, and the heatmaps reflect that.
— Reshmi